ゼロから作るDeepLearning 第3章 ニューラルネットワーク でとったノート
ゼロから作るDeep Learning 第3章 ニューラルネットワークを読んで取ったノートです.ご参考になれば幸いです.
本はこちら.

一つ目の式をより丁寧に書くと, $$ \begin{align*} a &= b + w_1x_1 + w_2x_2\\ y &= h(a)\\ \end{align*} $$
- $h(x)$: 活性化関数 (activation function)
活性化関数は入力信号の総和がどのように活性化するかということを決定する.
def step_function(x):
return int(x > 0)
np.ndarrayを入力できるように書き換え
def step_function(x):
return (x > 0).astype(np.int64)
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 13
plt.rcParams['font.family'] = 'Helvetica'
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
fig, ax = plt.subplots(dpi=100, facecolor='white')
ax.plot(x, y)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_ylim(-0.1, 1.1)
fig.tight_layout()
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.array([-1.0, 1.0, 2.0])
sigmoid(x)
array([0.26894142, 0.73105858, 0.88079708])plt.close()
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
fig, ax = plt.subplots(dpi=100, facecolor='white')
ax.plot(x, y)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_ylim(-0.1, 1.1)
fig.tight_layout()
def relu(x):
return np.maximum(0, x)
A = np.array([1, 2, 3, 4])
A
array([1, 2, 3, 4])np.ndim(A)
1A.shape
(4,)A.shape[0]
4B = np.array([[1, 2], [3, 4], [5, 6]])
B
array([[1, 2],
[3, 4],
[5, 6]])np.ndim(B)
2B.shape
(3, 2)A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
np.dot(A, B)
array([[19, 22],
[43, 50]])A = np.array([[1, 2, 3], [4, 5, 6]])
B = np.array([[1, 2], [3, 4], [5, 6]])
A.shape, B.shape
((2, 3), (3, 2))np.dot(A, B)
array([[22, 28],
[49, 64]])C = np.array([[1, 2], [3, 4]])
A.shape, C.shape
((2, 3), (2, 2))try:
np.dot(A, C)
except ValueError as e:
print('{0}\nとエラーメッセージが表示される.'.format(e))
shapes (2,3) and (2,2) not aligned: 3 (dim 1) != 2 (dim 0)
とエラーメッセージが表示される.
A = np.array([[1, 2], [3, 4], [5, 6]])
B = np.array([7, 8])
A.shape, B.shape
((3, 2), (2,))np.dot(A, B)
array([23, 53, 83])X = np.array([1, 2])
W = np.array([[1, 3, 5], [2, 4, 6]])
W, X.shape, W.shape
(array([[1, 3, 5],
[2, 4, 6]]),
(2,),
(2, 3))np.dot(X, W)
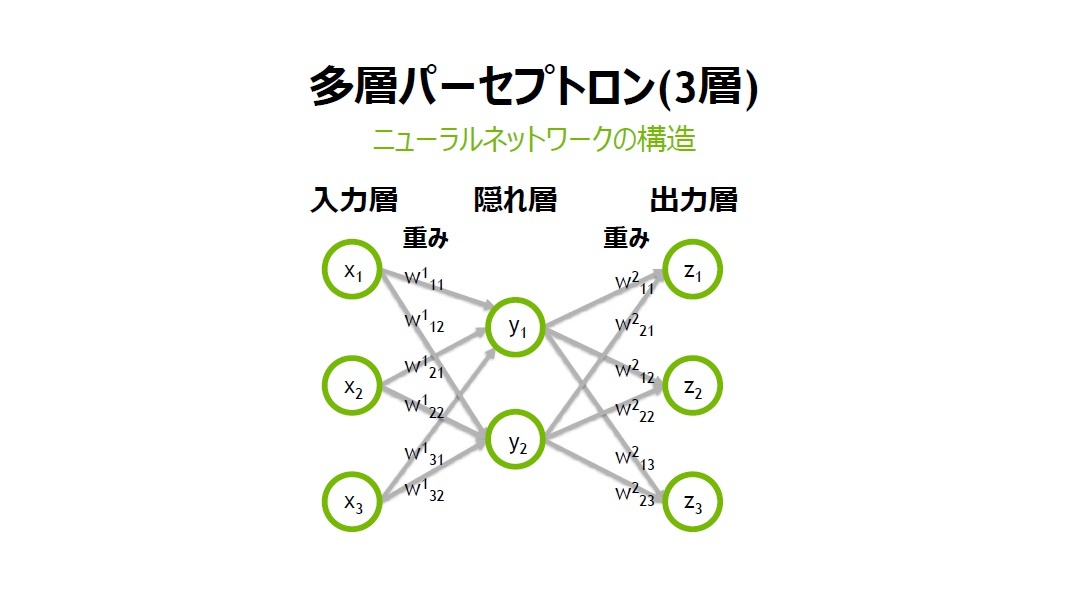
array([ 5, 11, 17])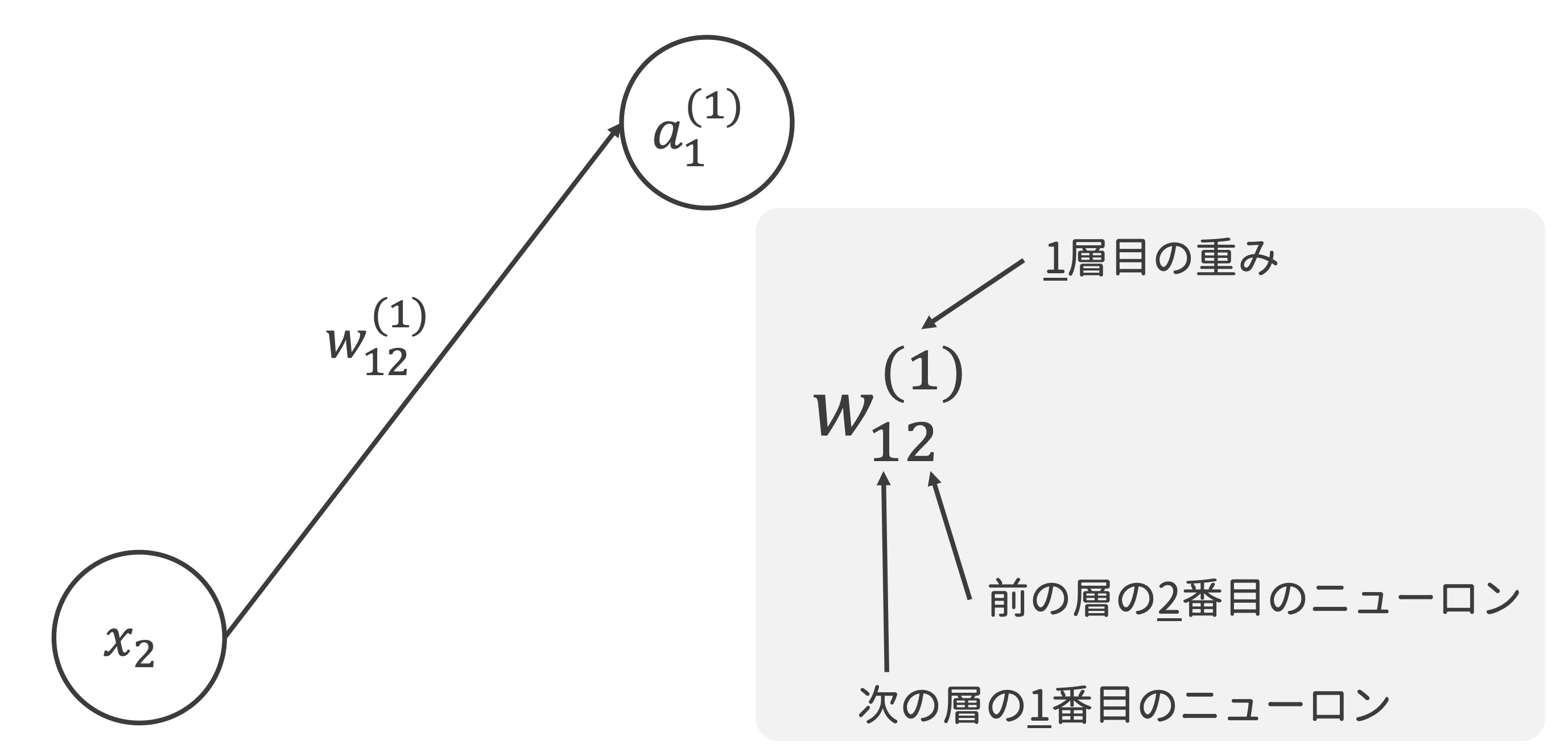
これを行列で表すと $$ A^{(1)} = XW^{(1)} + B^{(1)} $$ ただし, $$ A = \left( \begin{array}{ccc} a_1^{(1)} a_2^{(1)} a_3^{(1)}\\ \end{array} \right)\\ X = \left( \begin{array}{ccc} x_1 x_2\\ \end{array} \right)\\ B = \left( \begin{array}{ccc} b_1^{(1)} b_2^{(1)} b_3^{(1)}\\ \end{array} \right)\\ W = \left( \begin{array}{ccc} w_{11}^{(1)} w_{21}^{(1)} w_{31}^{(1)}\\ w_{12}^{(1)} w_{22}^{(1)} w_{32}^{(1)}\\ \end{array} \right)\\ $$
これらをNumpyで実装.
入力層から第1層
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
X.shape, W1.shape, B1.shape
((2,), (2, 3), (3,))A1 = np.dot(X, W1) + B1
A1
array([0.3, 0.7, 1.1])Z1 = sigmoid(A1)
Z1
array([0.57444252, 0.66818777, 0.75026011])第1層から第2層
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
Z1.shape, W2.shape, B2.shape
((3,), (3, 2), (2,))A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
第2層から出力層
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3)
Y
array([0.31682708, 0.69627909])ここでのidentity_functionは恒等関数.
出力層への伝達で使われる活性化関数は,$\sigma(x)$として表され,他の活性化関数とは区別して扱われる.
def init_network():
network = dict(
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]),
b1 = np.array([0.1, 0.2, 0.3]),
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]]),
b2 = np.array([0.1, 0.2]),
W3 = np.array([[0.1, 0.3], [0.2, 0.4]]),
b3 = np.array([0.1, 0.2]),
)
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# 入力層から第1層
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
# 第1層から第2層
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
# 第2層から出力層
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
y
array([0.31682708, 0.69627909])ソフトマックス関数を実装.
a = np.array([0.3, 2.9, 4.0])
exp_a = np.exp(a)
exp_a
array([ 1.34985881, 18.17414537, 54.59815003])sum_exp_a = np.sum(exp_a)
sum_exp_a
74.1221542101633y = exp_a / sum_exp_a
y
array([0.01821127, 0.24519181, 0.73659691])関数化すると,
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
ソフトマックス関数の実装上の注意
オーバーフロー問題:指数関数は容易に膨大な桁数になってしまう可能性があり,数値が「不安定」になってしまう.
これを解決するため以下の式変形を行う. $$ \begin{align*} y_k &= \frac{\mathrm{exp}\ a_k}{\displaystyle \sum_{i=1}^n \mathrm{exp}\ a_i}\\ &= \frac{C' \mathrm{exp}\ a_k}{\displaystyle C' \sum_{i=1}^n \mathrm{exp}\ a_i}\\ &= \frac{\mathrm{exp}\ \left(a_k + \mathrm{log}\ C' \right)}{\displaystyle \sum_{i=1}^n \mathrm{exp}\ \left( a_i + \mathrm{log}\ C' \right)}\\ &= \frac{\mathrm{exp}\ \left(a_k + C \right)}{\displaystyle \sum_{i=1}^n \mathrm{exp}\ \left( a_i + C \right)}\hspace{100px}(C = \mathrm{log}\ C')\\ \end{align*} $$ このとき,$C', C$は任意の定数.
オーバーフローしてしまう例
a = np.array([1010, 1000, 990])
np.exp(a) / np.sum(np.exp(a))
<ipython-input-37-23103c906500>:2: RuntimeWarning: overflow encountered in exp
np.exp(a) / np.sum(np.exp(a))
<ipython-input-37-23103c906500>:2: RuntimeWarning: invalid value encountered in true_divide
np.exp(a) / np.sum(np.exp(a))
array([nan, nan, nan])そこで先程の式変形の要領で改善してみる.
c = np.max(a)
a - c
array([ 0, -10, -20])np.exp(a - c) / np.sum(np.exp(a - c))
array([9.99954600e-01, 4.53978686e-05, 2.06106005e-09])def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # オーバーフロー対策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
y
array([0.01821127, 0.24519181, 0.73659691])np.sum(y)
1.0y[0]: 1.8 %の確率y[1]: 24.5 %の確率y[2]: 73.7 %の確率
と解釈することができ,確率的(統計的)な対応が可能!
注意点
- ソフトマックス関数を適用しても大小関係は変わらない.
- 指数関数が単調増加関数であることに起因
- 実際の問題で分類を行う際ソフトマックス関数は省略されることが一般的.
import sys, os
sys.path.insert(0, os.path.dirname(os.path.abspath(''))) # 上の階層のモジュールをインポートすることができないので.
from dataset.mnist import load_mnist
(X_train, t_train), (X_test, t_test) = load_mnist(flatten=True, normalize=False)
from PIL import Image
def img_show(img):
# numpy.ndarray to PIL用データオブジェクト
pil_img = Image.fromarray(np.uint8(img))
return pil_img # jupyter notebookなので書き換えた.
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
label
5img.shape
(784,)# 一辺の大きさ
a = int('{0:.0f}'.format(np.sqrt(img.shape[0])))
img = img.reshape(a, a)
img.shape
(28, 28)img_show(img)

import pickle
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open('sample_weight.pkl', 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
from tqdm.notebook import tqdm
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in tqdm(range(len(x))):
y = predict(network, x[i])
p = np.argmax(y)
if p == t[i]:
accuracy_cnt += 1
print('Accuracy: {0:.4f}'.format(accuracy_cnt/len(x)))
Accuracy: 0.9352
正規化 (normalization) という前処理 (pre-processing) を行っている.
x, _ = get_data()
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
x.shape
(10000, 784)x[0].shape
(784,)W1.shape, W2.shape, W3.shape
((784, 50), (50, 100), (100, 10))さっきの実装は一枚ずつ予測していた.→ バッチ処理したい!
- バッチ処理: まとめて計算する.
- 一枚あたりの処理時間を減らせる.
x, t = get_data()
network = init_network()
batch_size = 100 # バッチの数
accuracy_cnt = 0
for i in tqdm(range(0, len(x), batch_size)):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print('Accuracy: {:.4f}'.format(accuracy_cnt / len(x)))
Accuracy: 0.9352
